Legacy Systems Are Everywhere
Legacy systems are everywhere. They do the job, but most of the time they lack in performance and usability. The solution is usually a new system.
But how do we create a new system using the old data source? You can’t just freeze everything, rewrite, and flip a switch. In practice, the scope grows, the old system keeps accumulating changes, and the new system is perpetually “six months from done.”
The Strangler Fig Pattern
Martin Fowler described the Strangler Fig pattern, named after the tree that grows around a host, drawing from it until the host eventually dies and the fig stands alone.
The idea: instead of replacing the system in one move, you grow the new system around the old one, redirect capabilities one at a time, and decommission the legacy only after the new system has proven itself.
The key properties:
- Incremental replacement: Capabilities move one at a time, not all at once
- Seam-based routing: A facade (API gateway, adapter, or feature flag) decides which system handles each request
- Both systems run simultaneously: During the transition, they must stay in sync
That last point is where most Strangler Fig migrations struggle. If the new system reads stale data from the legacy store, it makes wrong decisions. Polling the old database adds lag and load. Dual writes (writing to both systems on every transaction) couple the two codebases and create risk during outages.
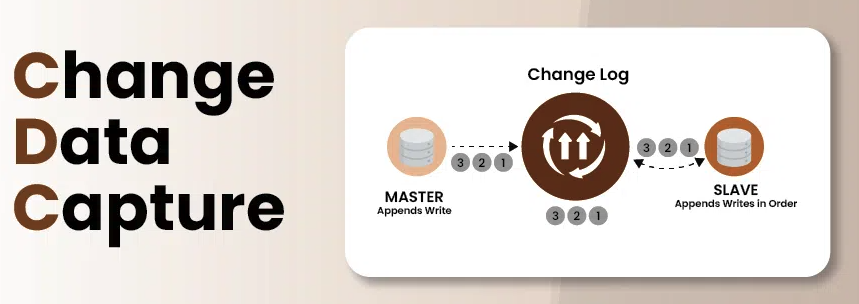
CDC eliminates all three problems.
CDC to the Rescue
Change Data Capture works by reading the database’s write ahead log instead of querying the tables. In MariaDB/MySQL this is the binary log (binlog), an ordered, durable record of every insert, update, and delete the database has committed.
This has three important properties:
- Minimal performance impact: Reading the binlog is read-only, no locks, no query load on production tables
- Real-time sync: Delivers events within milliseconds of commit, not on a polling schedule
- Zero-downtime migration: Keeps the target system in sync with the source during live cutovers
Enabling the Binary Log on MariaDB
Copy this configuration file into /etc/mysql/conf.d/cdc.cnf:
[mysqld]
log-bin=mysql-bin
binlog_format=ROW
binlog_row_image=FULL
server-id=1
expire_logs_days=7
Copy it into the container:
sudo docker cp cdc.cnf mariadb:/etc/mysql/conf.d/cdc.cnf
Check if the binary log is active:
sudo docker exec -it mariadb mysql -uroot -proot -e "SHOW VARIABLES LIKE 'log_bin';"
Does enabling binary logs impact read performance? Generally, no. It adds overhead only to write operations (INSERT, UPDATE, DELETE) because changes are written to disk twice, once to the table and once to the binlog. Pure reads (SELECT) are largely unaffected.
Debezium
Debezium is the open-source library that tails the binlog for you. It supports MariaDB, MySQL, PostgreSQL, Oracle, SQL Server, and more.
Crucially, it can run in embedded mode, as a library inside your JVM process, with no separate Debezium server to operate.
When Debezium starts against a database for the first time, it performs an initial snapshot: a consistent read of every row, emitted as READ events. Once the snapshot is done, it switches to tailing the binlog for live changes (CREATE, UPDATE, DELETE). The binlog offset is stored persistently so restarts resume from where they left off.
A Two-Phase Architecture
The core insight is that snapshot events and live events have different characteristics and should be handled differently.
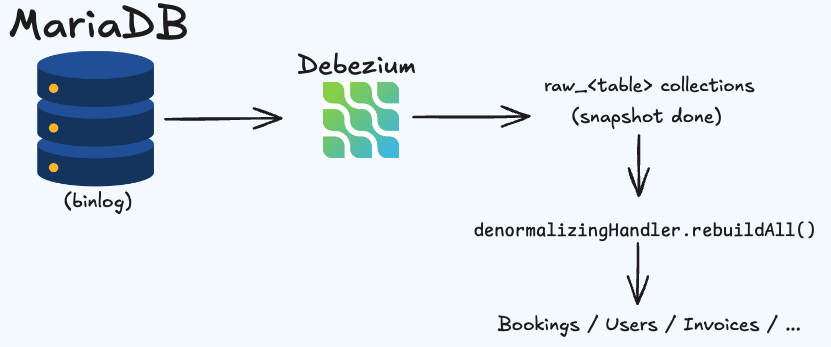
Phase 1 - Raw Mirror
Every incoming event, snapshot or live, is written 1:1 to a raw_<table> collection in MongoDB. The structure mirrors the relational row exactly: foreign key columns preserved as integer IDs, no joins, no normalization.
This phase is fast (one write per event), safe (raw data is replayable if something goes wrong in denormalization), and recoverable (you can re-run denormalization without re-running the snapshot).
Phase 2 - Denormalization
Once the snapshot completes, rebuildAll() is called on each registered handler. These handlers read from the raw_* collections, resolve foreign keys, embed related objects, and write the final document model.
For example, a bookings document might embed the booking status label, the list of passengers, and a payment summary, all joined from their respective raw_* collections.
Why Two Phases?
The snapshot can take minutes or hours for large tables. Writing denormalized documents during the snapshot would be unsafe because the raw data is incomplete, you would embed partial passenger lists or stale totals. By writing only to raw_* during the snapshot and denormalizing after it completes, this risk is avoided entirely.
After the snapshot, live CDC events update both the raw collection and the denormalized collection incrementally.
Snapshot Completion Detection
Knowing exactly when the snapshot ends is not trivial. The architecture uses three layers in priority order:
- Debezium
snapshot=lastfield: Debezium marks the final snapshot row with this field. When detected, rebuild is triggered immediately. - First non-READ event: During the snapshot, all events are
READ. The moment aCREATE,UPDATE, orDELETEarrives, the snapshot must be over. This is the fallback. - 30-second idle timeout: If the database is quiet after the snapshot (no live writes), neither of the above will fire. A scheduled job triggers the rebuild after 30 seconds of inactivity.
All three layers call the same triggerRebuild() method, which is synchronized — it fires exactly once regardless of which layer gets there first.
The cdc-sync Library
I packaged this architecture as a reusable Spring Boot autoconfiguration library called cdc-sync.
It provides:
- Transport abstraction: Direct (same JVM), Redis Streams, or Kafka controlled by a single config property
- Snapshot detection: The three-layer strategy above, built in
- Event dispatch: Routes events to all registered handler beans
- Rebuild invocation: Calls
rebuildAll()on allDenormalizingHandlerbeans after the snapshot
What it does not provide: no database writes, no schema opinions, no MongoDB dependency. The consumer implements the handlers and decides where data goes.
The Core Types
public record CdcEvent(
String operation, // READ, CREATE, UPDATE, DELETE
String collection, // Source table name
String documentId, // PK value(s) from the source table
String before, // JSON snapshot of row before change (null for CREATE)
String after, // JSON snapshot of row after change (null for DELETE)
boolean lastSnapshot // true if this is the last row of the initial snapshot
) { }
public interface CdcEventHandler {
void handle(CdcEvent event);
}
public interface DenormalizingHandler extends CdcEventHandler {
void rebuildAll(boolean dropFirst);
}
Implementing Handlers
Register handler beans as @Service, the library discovers them automatically:
@Service
public class RawBookingHandler implements CdcEventHandler {
private final MongoTemplate mongo;
@Override
public void handle(CdcEvent event) {
if ("bookings".equals(event.collection())) {
Document doc = Document.parse(event.after());
doc.put("_id", event.documentId());
mongo.save(doc, "raw_bookings");
}
}
}
@Service
public class BookingDenormalizingHandler implements DenormalizingHandler {
@Override
public void handle(CdcEvent event) {
// Incremental live update after snapshot is done
}
@Override
public void rebuildAll(boolean dropFirst) {
if (dropFirst) mongo.dropCollection("bookings");
// Read from raw_bookings, raw_booking_persons, etc.
// Assemble and write the denormalized booking document
}
}
No @EnableXxx annotation needed. Adding a new denormalized collection is just a new @Service class.
Configuration
debezium:
databaseHostname: localhost
databasePort: "3306"
databaseUser: debezium
databasePassword: secret
databaseIncludeList: "mydb"
tableIncludeList: "mydb.bookings,mydb.booking_persons"
snapshotMode: "initial"
offsetStorage: "io.debezium.storage.jdbc.JdbcOffsetBackingStore"
offsetStorageTableName: "offsets.test"
offsetStorageUrl: "jdbc:mysql://localhost:3306"
cdc:
transport: direct # direct | redis | kafka
rebuild:
drop-on-snapshot: true # false = safe restart (upsert, no drop)
Transport Modes
| Mode | When to Use |
|---|---|
direct | Single JVM, simplest setup. Best for initial migration. |
redis | Distributed, event persistence via Redis Streams. |
kafka | Multi-consumer, high-throughput, durable at scale. |
All three modes produce the same CdcEvent records and invoke handlers identically, swapping transports is a config-only change.
The Migration Lifecycle
Here is how cdc-sync slots into the three phases of a Strangler Fig migration:
Phase 1 - Transition: The legacy system runs normally. The CDC pipeline mirrors every change into raw_* collections and the denormalized view. The new system reads its own data directly and reads legacy records through an adapter that translates the CDC mirror on the fly. Writes always go to the new system.
Phase 2 - Cutover: A one-shot migration job reads the denormalized CDC mirror, transforms each document (field mapping, UUID generation from legacy integer IDs), and inserts into the new database. Because the mirror is continuously updated, the job can run repeatedly, the final run closes the gap to zero. The CDC pipeline keeps running during the rollback window.
Phase 3 - Decommission: Once the new system is the source of truth, the CDC pipeline is shut down. The MongoDB mirror is retained as an immutable record of the legacy data.
Summary
| Concern | Solution |
|---|---|
| Consistency during transition | CDC via Debezium binlog tailing |
| No impact on legacy system | Read-only binlog access |
| Snapshot safety | Two-phase: raw mirror first, denormalize after |
| Snapshot detection | 3-layer: snapshot=last, first non-READ, idle timeout |
| Transport flexibility | direct / Redis / Kafka, config-only switch |
| Incremental decommission | Strangler Fig: redirect capability by capability |
The cdc-sync library provides the transport, detection, and dispatch machinery. The consumer provides the handlers. Adding a new denormalized collection is a single @Service class, the rest is wired automatically.